SignStream: a tool for linguistic and computational research on visual-gestural language data
C. Neidle and S. Sclaroff
CAS Modern Foreign Languages, Boston University, Boston, MA, U.S.A.
Research on recognition and generation of signed languages and the gestural component of spoken languages has been held back by the unavailability of large-scale linguistically annotated corpora of the kind that led to significant advances in the area of spoken language. A major obstacle to the production of such corpora has been the lack of computational tools to assist in efficient analysis and transcription of visual language data.
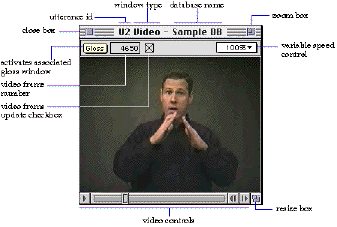
Figure 1a. SignStream: video and gloss windows.
The first part of this talk will present SignStream, a computer program that we have designed to facilitate the transcription and linguistic analysis of visual language data. SignStream provides a single computing environment for manipulating digital video and linking specific frame sequences to simultaneously occurring linguistic events encoded in a fine-grained multi-level transcription. Items from different fields are visually aligned on the screen to reflect their temporal relations, as illustrated in Figure 1.
We will describe the capabilities of the current release - which is distributed on a non-profit basis to educators and researchers - as well as additional features currently under development.
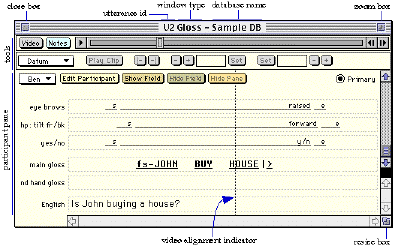
Figure 1b. SignStream: video and gloss windows.
Although SignStream may be of use for the analysis of any visual language data (including data from signed languages as well as the gestural component of spoken languages), we have been using the program primarily to analyze data from American Sign Language (ASL). This has resulted in a growing corpus of linguistically annotated ASL data (as signed by native signers). In the second part of this talk, we will discuss the ways in which the annotated corpus is being used in the development and refinement of computer vision algorithms to detect linguistically significant aspects of signing and gesture. This research is being conducted within the context of the National Center for Sign Language and Gesture Resources, which has established state-of-the-art digital video data collection facilities at Boston University and the University of Pennsylvania. Each lab is equipped with multiple synchronized digital cameras (see Figure 2) that capture different views of the subject (see Figure 3).
The video data collected in this facility are being made publicly available in multiple video file formats, along with the associated linguistic annotations.
Figure 2. National Center for Sign Language and Gesture Resources: data collection facility at Boston University.
Figure 3. Three views of a signer
The projects described here have been supported by grants from the National Science Foundation.
Paper presented at Measuring Behavior 2000, 3rd International Conference on Methods and Techniques in Behavioral Research, 15-18 August 2000, Nijmegen, The Netherlands