Facial expression analysis for assisted technology
R. Reilly, P. Scanlon and N. Fox
Department of Electronic Engineering, University College Dublin, Dublin, Ireland
Augmentative and alternative communication (AAC) systems are methods, which provide enhanced communication possibilities. A major goal of AAC is to provide access to technology for those without the fine motor control necessary to drive the 'standard' interfaces such as keyboard and mouse. It is generally accepted that users can 'adapt' their response to suit the interface device. A more appropriate solution would allow the system to adapt to the user and thus increase the flexibility of AAC systems [1]. Analysing facial expression is a useful mechanism for AAC. One application for rehabilitation is visual speaker identification, where the system recognises the speaker and provides personalised rehabilitation.
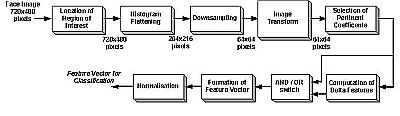
Research into speechreading has shown that through dynamically tracking of a small number of visual features from the face, a small number of words based on viseme recognition can be recognized with high accuracy [2]. Figure 1 summarizes the processing steps in this study. The Discrete Cosine Transform (DCT) was employed, with the highest energy coefficients used as the feature vector for classification.
Figure 1. The visual subsystem.
In addition to the transform coefficient features, temporal difference information or delta features between image frames are also calculated. Given frame k, delta features are computed between frame n and n-k, where N is the number of frames per utterance and k = 1, N/3, N/2, N*2/3, N*5/6, N-1 (See Figure 2). An audio-visual database employed in this study consisted of 10 speakers, each uttering the same 78 words [3]. A classification topology was constructed with 10 whole word left-to-right HMM models, representing the 10 speakers, each with 5 states and one Gaussian mixture per state.
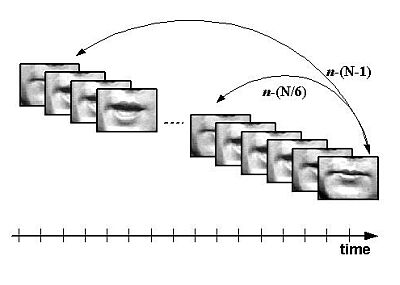
Figure 2. Visual memory features.
The outcome of this small study is that visual recognition was found to be maximized at k = N/6 for all repetitions and seen to increase with the number of repetitions included in the training data. The study shows that geometric details of the mouth region as well as its dynamic movements are required to better identify a speaker. This provides a mechanism for persons unable to vocalize, to control systems through articulation movement. Research has also shown that these dynamic features can be used as a form of person identification.
Current research is on developing on-line tremor suppression algorithms. An expression recogniser is currently being developed to allow recognition of user specific facial expressions. This would allow, with the aid of a Therapist, to train the system to an individual's needs. This research outlined provides the possibility to assess human-computer interaction and allow experimentation to improve the quality of augmentative and alternative communication.
References
Paper presented at Measuring Behavior 2002, 4th International Conference on Methods and Techniques in Behavioral Research, 27-30 August 2002, Amsterdam, The Netherlands
© 2002 Noldus Information Technology bv